Coursera - Introduction to Big Data
关于这门课
最近在Coursera上完成了一门课,Introduction to Big Data,是加州大学圣地亚哥分校(UCSD)计算机系开设的一门大数据入门课程。这门课属于Coursera上的一个Specification,Big Data,是这个Specification的第一门课,共6门课。
“Big Data Specification”
Introduction to Big Data - 3 weeks - 6 h/week
Big Data Modeling and Management Systems - 6weeks - 3 h/week
Big Data Integration and Processing - 6weeks - 5 h/week
Machine Learning with Big Data - 5 weeks - 5h/week
Graph Analytics for Big Data - 4 weeks - 5 h/week
Big Data - Capstone Project 6 weeks - 5h/week
(3 + 6 + 6 + 5 + 4 + 6) = 30 weeks
第一门课只有三周,是个导论性质的Introduction性的课,前两周主要介绍了Big Data中的一种重要的基础概念,和一些foundation Components。第三周是Get started with Hadoop。
一些笔记
Week One
Key Points:
- What launched the big data era?
- The growing data torrent
- Cloud Computing
- both these 2 thing combined together and make it possible to do big data analysis
- Data Integration
- Reduce data complexity
- Increase data availability
- Unify your data system
- Workflow with Big Data
- Big data –> Better models –> Higher precision
Week Two
Key Points:
-
How to describe big data?
We use V s:
- Volume == Size
- Challenge: Storage + Access + Processing(Performance)
- Velocity == Complexity & Speed, real-time processing
- Batch processing
- Collect data -> clean data -> feed in chunks -> wait -> act
- Real time processing
- Instantly capture streaming data -> feed real time to machines -> process real time -> act
- Prevent missed opportunities
- Batch processing
- Variety == increasing differences, type
- Veracity == quality - vary greatly
- Define the quality of data
- Uncertain
- Valence == Connectedness
- Connection increase -> challenges -> complex data exploration algorithm
- Value
- Volume == Size
-
Define the question
- Big data -> Analysis question -> insight ==> -<
- Strategy
- Aim
- Policy
- Plan
- Action
- P’s
- People
- Purpose
- Process
- Platforms
- Programmability
- ==> data product
- Process
- Define the problem -> access the situation -> define the goals and criteria -> formulate the question
-
Data Analysis
- Acquire Data
- Explore Data -> data understanding
- Prepare - Pre-Processing - filter - clean - sub-setting - data quality
- Analyze
- Classification
- Clustering
- Graph Analytics
- Regression
- Association Analysis
- Report - Purpose
- Act
Week Three
Key Points:
-
What is a distributed file system?
-
Scalable computing over the internet
-
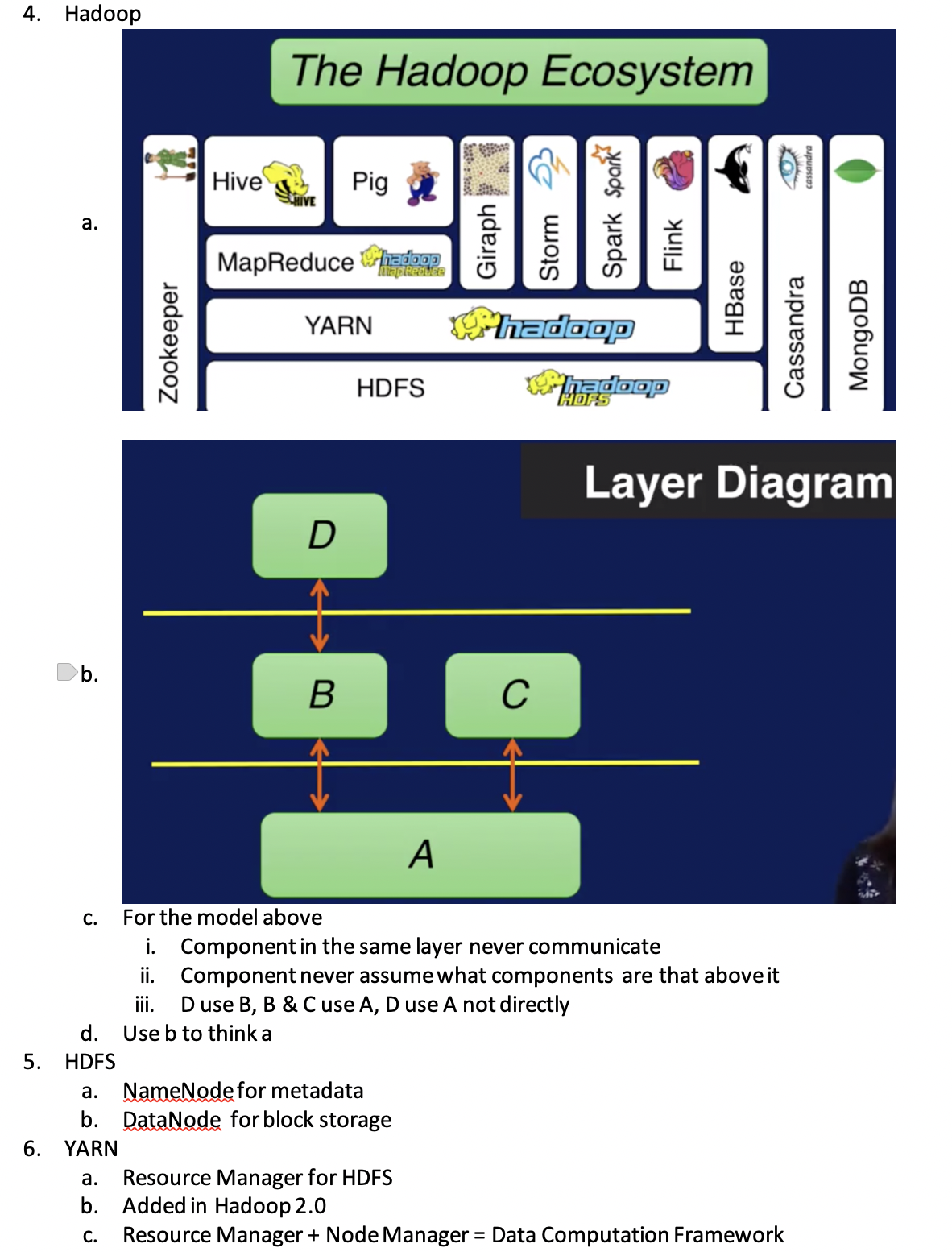
Programming Models for Big Data
-
-
Abstraction -> Runtime libraries + Programming language
-
Requirements
-
-
- Support Big Data Operations
-
- Split volumes of data
- Access data fast
- Distribute computations to nodes
-
- Handle Fault Tolerance
-
- Replicate data partitions
- Recover files when needed
-
- Enable adding more racks - Enable scale out
-
- Optimized for specific data types
-
-
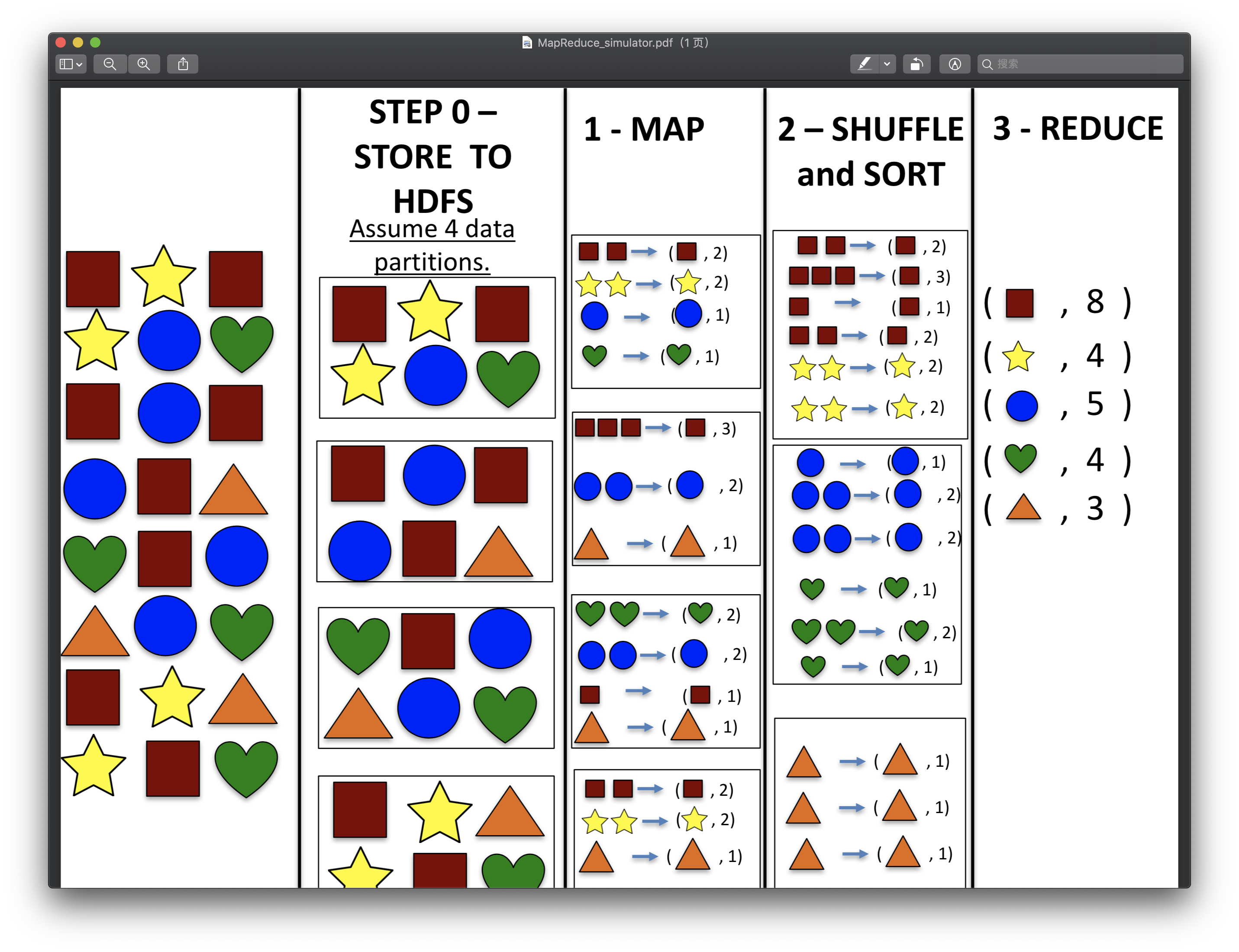
One Instance of Programming Models: MapReduce
-
And Hadoop is one implement of MapReduce
- Map -> apply, Reduce -> summarize
-

A Simulator for MapReduce